Die Architektur von Legal-Cloud-Software
13.04.2026
Für deutsche Anwaltskanzleien ist die Nutzung von Cloud-Diensten längst Alltag: E-Mail über Microsoft 365, Dokumentenverwaltung in SharePoint, Legal-Tech-Plattformen für Fristenkontrolle, Vertragsmanagement oder Dokumentenanalyse. Cloud-Software verspricht Effizienz, Skalierbarkeit und ortsunabhängiges Arbeiten.
Gleichzeitig berührt ihr Einsatz den sensibelsten Kern anwaltlicher Tätigkeit: die Verschwiegenheitspflicht nach § 43a BRAO und die Verantwortung für den Schutz hochvertraulicher Mandatsdaten. Um die daraus resultierenden Risiken sachgerecht beurteilen zu können, ist ein grundlegendes Verständnis der technischen Architektur von Cloud-Software erforderlich.
Was ist die Cloud? Grundlagen des Cloud-Computing
Definition: Cloud-Software vs. klassische Kanzlei-IT
Der Begriff "Cloud" bezeichnet die Bereitstellung von IT-Ressourcen über das Internet. Statt Software auf dem eigenen Server (On-Premise) oder Computer (On-Device) zu installieren und zu betreiben, greifen Nutzer über das Internet auf Anwendungen, Speicherplatz und Rechenleistung zu, die in der Regel von einem externen Anbieter bereitgestellt werden.

Die Kanzlei verlagert nicht nur den Betrieb, sondern regelmäßig auch zentrale Kontroll- und Steuerungsmöglichkeiten auf Dritte. Die physische Infrastruktur entzieht sich dem unmittelbaren Zugriff der Kanzlei; Einfluss besteht primär über Verträge und Konfigurationen.
Die 5 Kernmerkmale von Cloud-Computing (NIST-Definition)
Das US-amerikanische National Institute of Standards and Technology (NIST) definiert fünf charakteristische Eigenschaften von Cloud-Computing:
1. On-Demand Self-Service: Nutzer können Ressourcen wie zusätzlichen Speicherplatz oder weitere Nutzerlizenzen selbstständig und automatisch online anfordern, ohne mit dem Anbieter interagieren zu müssen.
2. Broad Network Access: Zugriff erfolgt über das Internet von verschiedenen Endgeräten.
3. Resource Pooling: Die Ressourcen des Anbieters werden gebündelt und dynamisch verschiedenen Kunden zugewiesen. Viele Kanzleien teilen sich dieselbe physische Hardware (Multi-Tenancy), sind aber logisch voneinander getrennt.
4. Rapid Elasticity: Ressourcen können schnell nach oben oder unten skaliert werden.
5. Measured Service: Die Nutzung wird automatisch gemessen und kontrolliert. Abrechnung erfolgt typischerweise nutzungsbasiert nach Anzahl der Nutzer, genutztem Speicherplatz oder übertragenen Datenmengen.
Resource Pooling und Broad Network Access haben unmittelbare Auswirkungen auf Kontrolle, Zugriffsmöglichkeiten und Abgrenzbarkeit von Daten.
Die drei Service-Modelle
Je nach Auslagerungstiefe unterscheidet man drei grundlegende Cloud-Modelle, die unterschiedliche Verantwortlichkeiten mit sich bringen:
Infrastructure as a Service (IaaS): Der Anbieter stellt grundlegende IT-Infrastruktur bereit – virtuelle Server, Speicherplatz, Netzwerke. Die Kanzlei bleibt verantwortlich für Betriebssystem, Middleware und Anwendungen. Beispiele: Amazon Web Services (AWS) EC2, Microsoft Azure Virtual Machines, Hetzner.
Platform as a Service (PaaS): Zusätzlich zur Infrastruktur stellt der Anbieter Betriebssysteme und Laufzeitumgebungen bereit. Entwickler können darauf Anwendungen erstellen, ohne sich um Server-Verwaltung kümmern zu müssen.
Software as a Service (SaaS): Für Kanzleien das praktisch relevanteste Modell. Die Anwendung wird vollständig vom Anbieter betrieben und über den Browser genutzt. Beispiele: Microsoft 365, DATEV-Cloud, Legal-Tech-Plattformen.
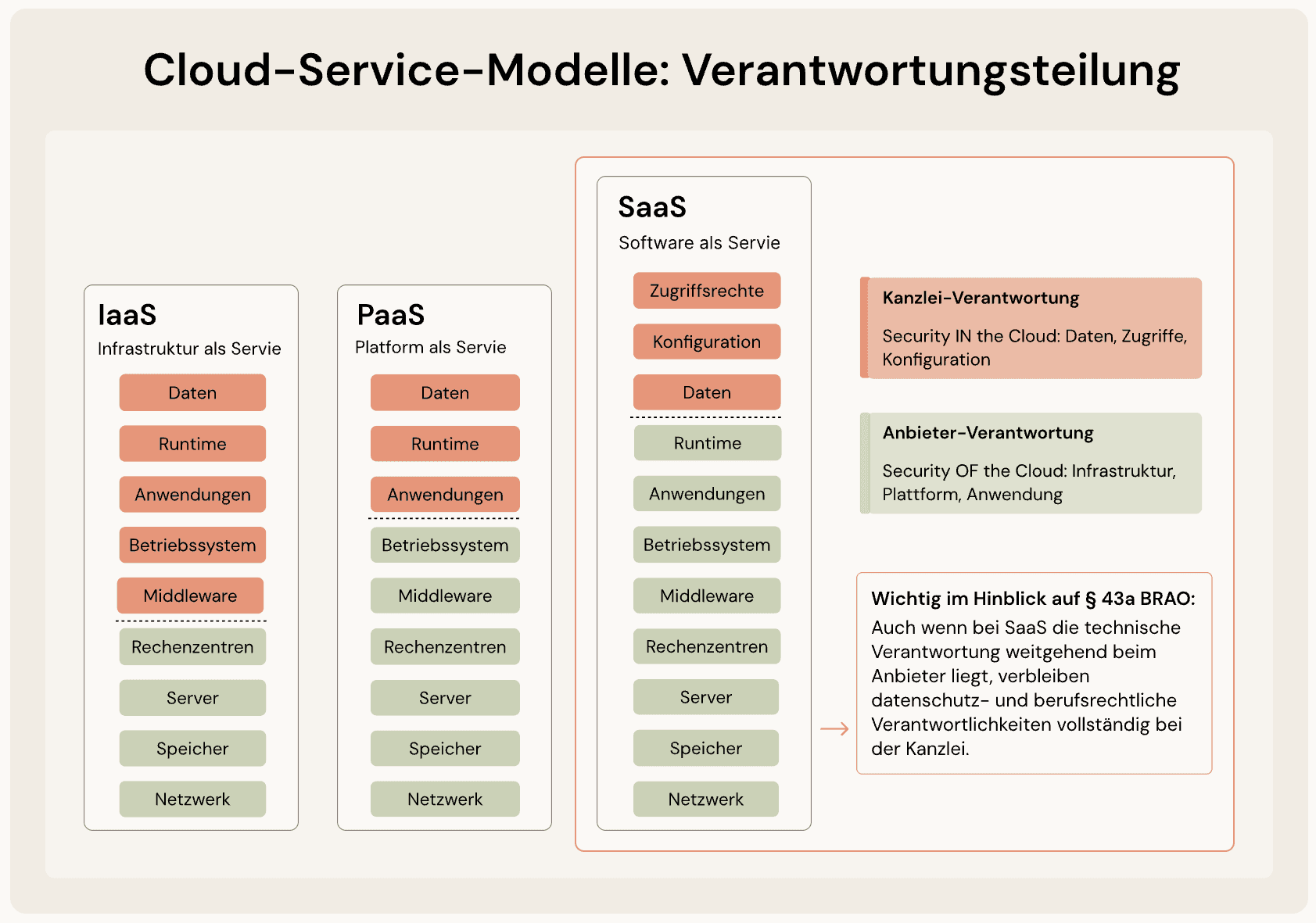
Auch wenn bei SaaS die technische Verantwortung weitgehend beim Anbieter liegt, verbleiben datenschutz- und berufsrechtliche Verantwortlichkeiten vollständig bei der Kanzlei. Diese strukturelle Entkopplung von technischer Kontrolle und rechtlicher Verantwortung ist eines der Grundprobleme der Cloud-Nutzung.
Der technische Aufbau von Cloud-Software
Cloud-Anwendungen folgen regelmäßig einer mehrstufigen, verteilten Architektur. Am Beispiel einer Legal-Tech-Plattform lassen sich die zentralen Ebenen verdeutlichen. Die konkrete technische Umsetzung variiert je nach Anbieter, die grundlegenden Architekturprinzipien bleiben jedoch vergleichbar.
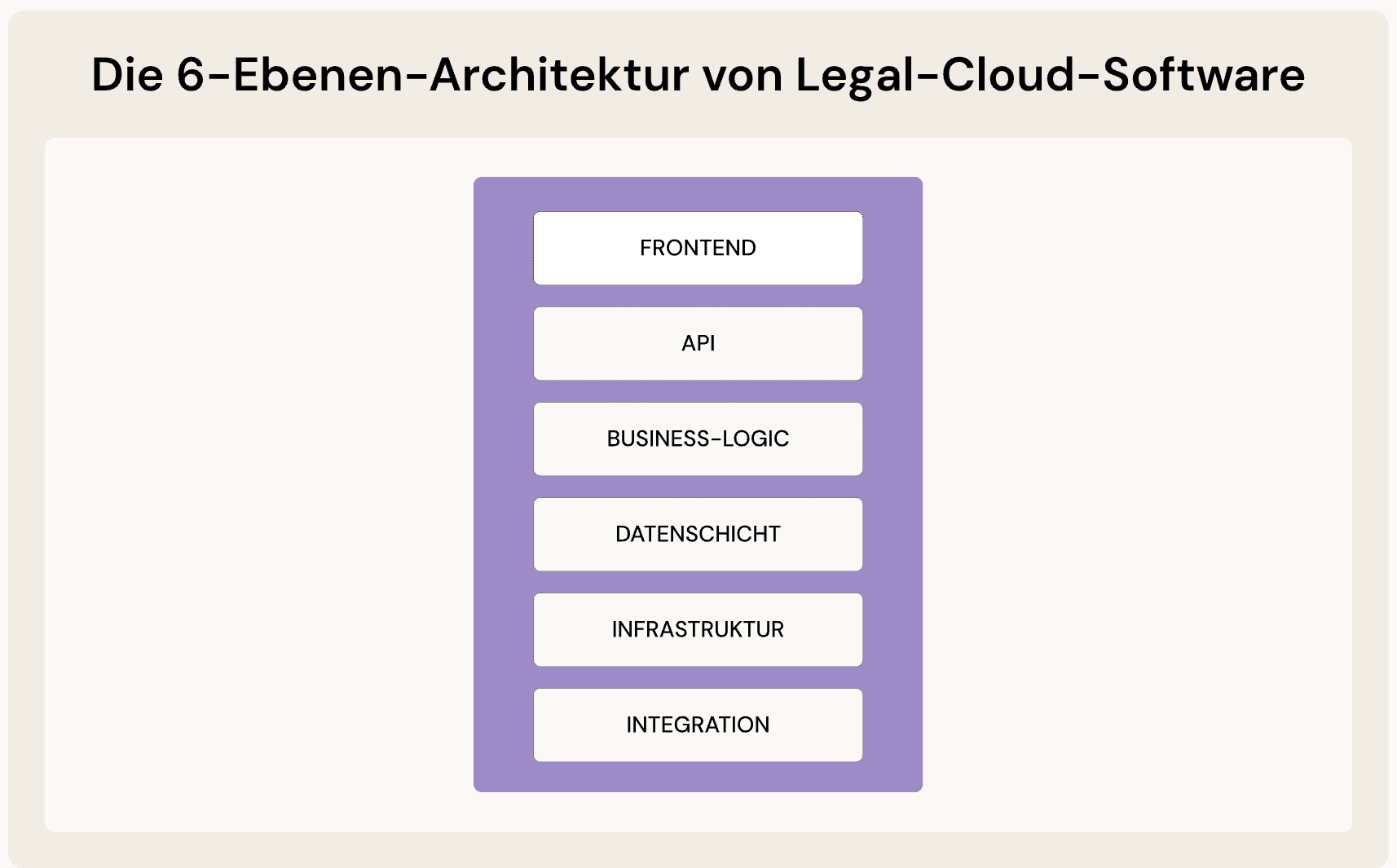
Die Frontend-Ebene: Die Benutzeroberfläche
Die Frontend-Ebene ist die Benutzeroberfläche – typischerweise eine Webanwendung im Browser oder eine mobile App. Diese besteht neben HTML (Struktur) und CSS (Styles) zum Beispiel aus JavaScript-Code (React, Angular, Vue.js), der im Browser des Nutzers läuft. (React, Angular, Vue.js), der im Browser des Nutzers läuft.
Wie wird das Frontend gebaut?
Moderne Frontend-Anwendungen werden nicht "von Grund auf" programmiert, sondern nutzen hunderte externe Software-Bibliotheken. Ein typisches React-basiertes Frontend setzt sich zusammen aus:
React selbst (UI-Bibliothek/Framework)
React Router (für Navigation zwischen Seiten)
Axios oder Fetch (für API-Kommunikation)
Formik oder React Hook Form (für Formulare)
Date-Picker, PDF-Viewer, Rich-Text-Editor (UI-Komponenten)
Dutzende weitere Utility-Bibliotheken
Diese Komponenten stammen von unterschiedlichen Entwicklern weltweit und werden über öffentliche Repositories wie npm (Node Package Manager) oder GitHub verteilt. Da jede dieser Bibliotheken wiederum eigene Abhängigkeiten mitbringt – sogenannte transitive Abhängigkeiten – umfasst ein typisches Frontend-Projekt in einer Node.js-Entwicklungsumgebung über 1.000 externe Pakete.
Jede Bibliothek ist ein potenzielles Sicherheitsrisiko.
Um schnelle Ladezeiten weltweit zu gewährleisten, werden statische Inhalte (JavaScript-Code, Bilder, CSS) über Content Delivery Networks (CDN) ausgeliefert – Netzwerke mit hunderten weltweit verteilten Servern, die Inhalte physisch näher zum Nutzer bringen und so die Ladezeiten deutlich verkürzen.
Dienste wie Cloudflare oder AWS CloudFront cachen, also zwischenspeichern, diese Inhalte in über 300 Rechenzentren weltweit. Wenn eine Legal-Tech-App geöffnet wird, lädt der Browser den Code nicht aus dem Hauptrechenzentrum, sondern vom geografisch nächsten CDN-Server – das macht die Anwendung spürbar schneller.
Auch wenn Mandatsdaten ausschließlich in Deutschland gespeichert sind, kann der Anwendungs-Code beim Laden ein globales Netzwerk durchlaufen, wenn der Anbieter globale CDNs nutzt. Es gibt auch regionale CDN-Anbieter, die Daten ausschließlich innerhalb bestimmter Regionen verarbeiten. Bei globalen CDNs werden dabei technische Metadaten (IP-Adresse, Browser-Typ, Zugriffszeitpunkt) weltweit verarbeitet.
Zur Frontend-Ebene gehört auch die Authentifizierung und Autorisierung – also die Prüfung der Identität des Nutzers und seiner Berechtigungen. Die Authentifizierung erfolgt häufig über externe Identitätsdienste wie Single Sign-On (SSO): Der Nutzer meldet sich einmal mit einem zentralen Konto an (z.B. Microsoft 365) und erhält damit automatisch Zugriff auf alle verbundenen Anwendungen – ohne sich bei jeder App separat anmelden zu müssen.
Gängige Anbieter sind Microsoft Entra ID (Standard für Microsoft-365-Kanzleien), Auth0 oder Okta. Bei jedem Login läuft die Authentifizierung über diesen externen Dienst, der Metadaten wie Anmeldezeitpunkte, verwendete Geräte und Netzwerk-Standorte speichert.
Bereits auf der Frontend-Ebene sind mehrere externe Dienstleister eingebunden – CDN-Anbieter für Code-Auslieferung, hunderte npm-Entwickler für Bibliotheken und Authentifizierungsdienste für den Login. Jeder dieser Akteure verarbeitet technische Daten, noch bevor Sie mit Mandatsdaten arbeiten.
Die API-Ebene: Die Kommunikationsschicht
Zwischen Frontend (was im Browser läuft) und Backend (wo die Geschäftslogik und Daten liegen) vermittelt eine API-Schicht.
Was ist eine API?
API steht für Application Programming Interface (Programmierschnittstelle). Eine API definiert, wie zwei Softwarekomponenten miteinander kommunizieren – welche Anfragen gestellt werden können, welche Parameter erforderlich sind und welche Antworten zurückkommen.
Funktionsweise: Wenn in der Anwendung eine Aktion ausgeführt wird (z.B. Akte öffnen), sendet der Browser eine strukturierte Anfrage an das Backend (z.B. GET/ api/cases/12345 mit Authentifizierungstoken). Das Backend verarbeitet diese Anfrage, prüft Berechtigungen und sendet die angeforderten Daten zurück. Die API ist somit die Schnittstelle zwischen Frontend und Backend.
Typische API-Operationen in Kanzleisoftware:
Die API-Schicht besteht aus mehreren Komponenten:
1. API Gateway: Der zentrale Zugriffskontrollpunkt
Das API Gateway fungiert als zentraler Einstiegspunkt für alle Anfragen. Seine Aufgaben umfassen:
Authentifizierung: Prüfung der Identität des anfragenden Nutzers (Ist das Session-Token gültig? Ist die Sitzung noch aktiv?)
Autorisierung: Prüfung der Zugriffsberechtigung (Darf Anwalt Müller auf Akte Schmidt zugreifen? Hat er die Rolle "Fallbearbeiter" oder nur "Leserechte"?)
Routing: Weiterleitung der Anfrage an den zuständigen Backend-Service (Case Management, Document Service, Billing Service)
Rate Limiting: Begrenzung der Anfragen pro Zeiteinheit zur Verhinderung von Missbrauch oder Denial-of-Service-Angriffen (z.B. maximal 100 Anfragen pro Minute pro Nutzer)
Logging: Protokollierung aller Zugriffe für Audit-Trails, Sicherheitsanalysen und DSGVO-Nachweispflichten
2. Load Balancer: Lastverteilung und Hochverfügbarkeit
Um hohe Lasten zu bewältigen und Ausfallsicherheit zu gewährleisten, verteilt ein Load Balancer eingehende Anfragen auf mehrere API-Gateway-Instanzen nach verschiedenen Algorithmen (Round Robin, Least Connections, IP-Hash). Bei gleichzeitigem Zugriff durch hunderte Anwälte (etwa montags morgens) bleibt die Anwendung so performant. Bei Ausfall einer Instanz erfolgt automatische Umleitung auf funktionierende Server (Failover).
Die API-Ebene trifft zentrale Zugriffsentscheidungen und verarbeitet sämtliche Kommunikationsdaten zwischen Nutzer und Backend. Fehlkonfigurationen – etwa unzureichende Autorisierungsprüfungen, fehlende Input-Validierung oder zu weit gefasste CORS-Policies – können zu unbefugten Datenzugriffen führen. Klassischer Schwachstellentyp: Broken Access Control (OWASP Top 10), bei dem Nutzer durch Manipulation von API-Parametern auf fremde Ressourcen zugreifen können.
Die Business-Logic-Ebene: Das Herz der Anwendung
In dieser Ebene werden die eigentlichen Funktionen der Anwendung ausgeführt. Moderne Legal-Tech-Systeme nutzen häufig Microservice-Architekturen. Im Gegensatz zu einer monolithischen Anwendung (eine große, zusammenhängende Software, bei der alle Funktionen in einem System gebündelt sind) besteht das System aus vielen kleinen, spezialisierten Diensten, die mehr oder weniger unabhängig voneinander arbeiten:
Typische Microservices in Legal-Tech-Plattformen:
Case Management Service: Verwaltet Akten, Mandate und Dokumente
Calendar Service: Handhabt Fristen und Termine
Billing Service: Zeiterfassung und Abrechnung
Document Service: Verarbeitet Dokumente, extrahiert Text per OCR
Search Service: Ermöglicht Volltextsuche in Akten
Notification Service: Versendet E-Mail- und Push-Benachrichtigungen
Jeder dieser Services läuft in einer isolierten Laufzeitumgebung (Container), die unabhängig gestartet, gestoppt und aktualisiert werden kann. Die Services kommunizieren untereinander über interne APIs. Verwaltungssysteme wie Kubernetes orchestrieren hunderte oder tausende solcher Services automatisch – sie starten ausgefallene Container neu, verteilen Last und skalieren bei Bedarf.
Die Services sind in verschiedenen Programmiersprachen geschrieben – typischerweise Python, Javascript oder Java. Jeder Service nutzt dutzende externe Bibliotheken und Frameworks für Standardaufgaben. In der Summe über alle Microservices hinweg können mehrere tausend externe Komponenten involviert sein.
Typische Microservices in Legal-Tech-Plattformen:
Case Management Service: Verwaltet Akten, Mandate und Dokumente
Calendar Service: Handhabt Fristen und Termine
Billing Service: Zeiterfassung und Abrechnung
Document Service: Verarbeitet Dokumente, extrahiert Text per OCR
Search Service: Ermöglicht Volltextsuche in Akten
Notification Service: Versendet E-Mail- und Push-Benachrichtigungen
Jeder dieser Services läuft in einer isolierten Laufzeitumgebung (Container), die unabhängig gestartet, gestoppt und aktualisiert werden kann. Die Services kommunizieren untereinander über interne APIs. Verwaltungssysteme wie Kubernetes orchestrieren hunderte oder tausende solcher Services automatisch – sie starten ausgefallene Container neu, verteilen Last und skalieren bei Bedarf.
Die Services sind in verschiedenen Programmiersprachen geschrieben – typischerweise Python, Javascript oder C#. Jeder Service nutzt dutzende externe Bibliotheken und Frameworks für Standardaufgaben. In der Summe über alle Microservices hinweg können mehrere tausend externe Komponenten involviert sein.
Die Architektur erhöht Skalierbarkeit und Ausfallsicherheit, führt aber zugleich zu einer Vielzahl interner und externer Abhängigkeiten, die für den Anwender kaum transparent sind.
Die Datenschicht: Wo Informationen gespeichert werden
Die Datenschicht ist für Kanzleien die kritischste Komponente, da hier Mandantendaten dauerhaft gespeichert werden:
Relationale Datenbanken: Strukturierte Daten wie Mandantenstammdaten, Rechnungen, Fristen oder Nutzerprofile werden in relationalen Datenbanken gespeichert – tabellenbasierte Systeme mit Zeilen, Spalten und Verknüpfungen zwischen Tabellen (ähnlich wie Excel, aber mit Relationen). Gängige Systeme: PostgreSQL, MySQL, Microsoft SQL Server. Cloud-Provider bieten verwaltete Dienste (Managed Database Services) wie AWS RDS oder Azure SQL Database, bei denen der Anbieter Installation, Updates, Backups und Skalierung übernimmt.
NoSQL-Datenbanken: Für flexible, unstrukturierte oder semi-strukturierte Daten werden NoSQL-Datenbanken eingesetzt – sie verzichten auf starre Tabellen und ermöglichen schnellere Abfragen bei großen, heterogenen Datenmengen:
MongoDB: Speichert JSON-ähnliche Dokumente (z.B. E-Mail-Verläufe, komplexe Dokumenten-Metadaten)
Elasticsearch: Ermöglicht Volltextsuche über Millionen Dokumente mit Millisekunden-Antwortzeit
Redis: Dient als schneller Cache (Zwischenspeicher) für häufig abgerufene Daten
Object Storage (Objektspeicher): Dateien wie PDF-Dokumente, E-Mail-Anhänge oder gescannte Akten werden in Object Storage-Systemen abgelegt – hochskalierbaren Cloud-Speichern, die Milliarden von Dateien effizient verwalten können. Im Gegensatz zu klassischen Dateisystemen (Ordner-Hierarchien) organisiert Object Storage Dateien als flache Liste mit eindeutigen IDs. Gängige Dienste: AWS S3, Azure Blob Storage, Google Cloud Storage. Diese Systeme replizieren Daten automatisch über mehrere Rechenzentren für Ausfallsicherheit.
Backup und Disaster Recovery: Daten werden regelmäßig gesichert, idealerweise nach dem 3-2-1-Prinzip:
3 Kopien der Daten
Auf 2 verschiedenen Speichermedien
Mindestens 1 Kopie an geografisch entferntem Standort
Bei Cloud-Diensten bedeutet das oft: Primärdaten am Standort A, Backups am Standort B und C. Diese Georedundanz sichert gegen Rechenzentrumsausfälle ab (Brand, Flut, Stromausfall), führt aber zu zusätzlichen grenzüberschreitenden Datenflüssen innerhalb und außerhalb der EU.
Auch wenn Anbieter Zusicherungen zu Speicherorten machen, entstehen hier regelmäßig komplexe Datenflüsse, die sich einer einfachen Kontrolle entziehen. Wo genau befinden sich Backups? Welche Mitarbeiter des Anbieters haben Zugriff?
Die Infrastruktur-Ebene: Die physische Grundlage
Unter allen Software-Schichten liegt das physische Fundament: die Infrastruktur-Ebene. Sie umfasst die Hardware, Rechenzentren und Netzwerke, auf denen Cloud-Dienste tatsächlich laufen. Für Kanzleien ist diese Ebene besonders relevant, da hier grundlegende Fragen zu Standort, Kontrolle und physischer Sicherheit beantwortet werden.
Rechenzentren: Cloud-Anbieter betreiben Rechenzentren – große, hochgesicherte Gebäude mit tausenden Servern, redundanter Stromversorgung, Klimatisierung und mehrstufiger physischer Sicherheit.
Auch wenn ein Anbieter „Daten nur in Deutschland" verspricht, existiert die Infrastruktur grundsätzlich global. Bei den meisten Cloud-Anbietern lässt sich jedoch eine konkrete Region oder ein spezifisches Rechenzentrum festlegen (z. B. Frankfurt oder Nürnberg). Wählt man „EU only", sollten die Daten die EU nicht verlassen – Georedundanz erfolgt dann in der Regel ausschließlich zwischen Rechenzentren innerhalb der festgelegten Region.
Auch wenn ein Anbieter "Daten nur in Deutschland" verspricht, existiert die Infrastruktur global. Für Georedundanz werden Daten zwischen mehreren Rechenzentren repliziert (z.B. Standort A + Standort B).
Virtualisierung: Auf der physischen Hardware läuft eine Virtualisierungsschicht (Hypervisor – Spezialsoftware wie VMware ESXi, KVM, Microsoft Hyper-V oder Xen), die einen physischen Server in viele virtuelle Maschinen (VMs) aufteilt. Jede VM verhält sich wie ein eigenständiger Computer. Zu beachten ist hier: Eine Kanzlei nutzt in der Regel keine dedizierten Server – die Hardware wird mit anderen Kunden geteilt, Trennung erfolgt nur durch Software-Isolation.
Netzwerk-Infrastruktur: Rechenzentren sind über Hochleistungsnetzwerke (100+ Gigabit Ethernet) miteinander verbunden – dedizierte Glasfaserleitungen zwischen geografischen Regionen (z.B. Standort A ↔ Standort B: ~10 Millisekunden Latenz). Sicherheit erfolgt durch Firewalls, DDoS-Schutz (Terabit-Kapazität), Intrusion Detection Systems.
Das Dilemma: Enterprise-Grade-Sicherheit – aber kein physischer Zugriff, Intransparenz und Abhängigkeit.
Die Integration-Ebene: Externe Dienste
Moderne Cloud-Anwendungen integrieren regelmäßig zahlreiche externe Dienste, die ihrerseits ebenfalls die hier genannte Infrastruktur nutzen und somit komplexe Abhängigkeiten aufweisen:
E-Mail-Versand: SendGrid, AWS SES, Mailgun
Zahlungsabwicklung: Stripe, PayPal, Adyen
Dokumentenverarbeitung: Adobe Sign, DocuSign, AWS Textract
Analytics: Google Analytics, Mixpanel
Monitoring: Datadog, New Relic, Sentry
Support-Chat: Intercom, Zendesk
Künstliche Intelligenz: OpenAI API, AWS Comprehend
Diese Dienste sind technisch sinnvoll, führen jedoch zu weiteren Akteuren in der Verarbeitungskette, die für Kanzleien häufig nur eingeschränkt sichtbar sind.
Fazit
Die technische Architektur moderner Legal-Cloud-Software ist leistungsfähig, hochgradig verteilt und stark von Drittkomponenten abhängig. Gerade diese Eigenschaften stehen jedoch in einem Spannungsverhältnis zu den berufs- und datenschutzrechtlichen Anforderungen an anwaltliche Tätigkeit.
Die Auslagerung technischer Funktionen geht regelmäßig mit einem Verlust unmittelbarer Kontrolle einher – ohne dass sich die rechtliche Verantwortung entsprechend verlagert.
Im folgenden Beitrag "Die Cloud-Risiken für Kanzleien" werden die daraus resultierenden Risiken systematisch analysiert: Supply-Chain-Risiken durch komplexe Abhängigkeiten, das häufig missverstandene Shared-Responsibility-Modell sowie die rechtlichen Konflikte grenzüberschreitender Datenverarbeitung.